
쓰지만 말고 직접 구현해보자! 분산 메시지큐!
MSA(Microservice Architecture)가 아키텍처 설계의 트랜드가 되면서 메시지 큐는 시스템 구성의 중요한 요소로 자리잡았습니다.
이번 글에서는 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 4장 분산 메시지 큐를 소개하려고 합니다.
분산 메시지 큐의 특징을 간단히 알아보고, 기본적인 요소를 설계해봅시다.
(메세지 큐를 구성하는 요소가 방대한 만큼 세부 개념에 대한 자세한 설명은 넘어가겠습니다.)
1. 메시지 큐 특징 알아보기
본격적인 설계에 앞서 메시지 큐의 기능을 생각해봅시다.
1. 프로듀서는 메시지 큐에 메시지를 보낼 수 있어야 합니다.
2. 컨슈머는 메시지 큐를 통해 메시지를 수신할 수 있어야 합니다.
3. 하나의 메시지를 서로 다른 컨슈머가 수신할 수 있어야 합니다.
4. 메시지가 생산된 순서대로 소비될 수 있도록 순서를 보장해야 합니다.
5. 오래된 이력 데이터는 삭제될 수 있습니다.
6. 메시지 크기는 킬로바이트 수준입니다.
7. 메시지는 최소 한 번, 최대 한 번, 정확히 한 번 가운데 설정할 수 있어야 합니다.`
메시지 큐의 비기능 요구사항은 3가지가 있습니다.
1. 높은 대역폭과 낮은 전송 지연 중 하나를 설정으로 선택 가능해야 합니다.
2. 메시지 양이 급증해도 처리 가능해야 합니다.
3. 데이터는 디스크에 보관되어야 하며 여러 노드에 복제되어야 합니다.
Kafka와 RabbitMQ의 차이점은 무엇인가요?
https://aws.amazon.com/ko/compare/the-difference-between-rabbitmq-and-kafka/
메시지큐와 Kafka의 기본적인 특징을 소개한 블로그입니다.
카프카가 무엇이고, 왜 사용하는 것 일까?
https://hudi.blog/what-is-kafka/
2. 메시지 전달 과정 알아보기
다음으로 프로듀서에서 발행한 메시지가 컨슈머까지 어떻게 전달되는지 흐름을 생각해봅시다.
책에서는 일대일 모델부터 단계적으로 소개하고 있지만, 이 글에서는 발행(Pub)-구독(Sub) 모델 기반의 최종 모습만 소개하겠습니다.
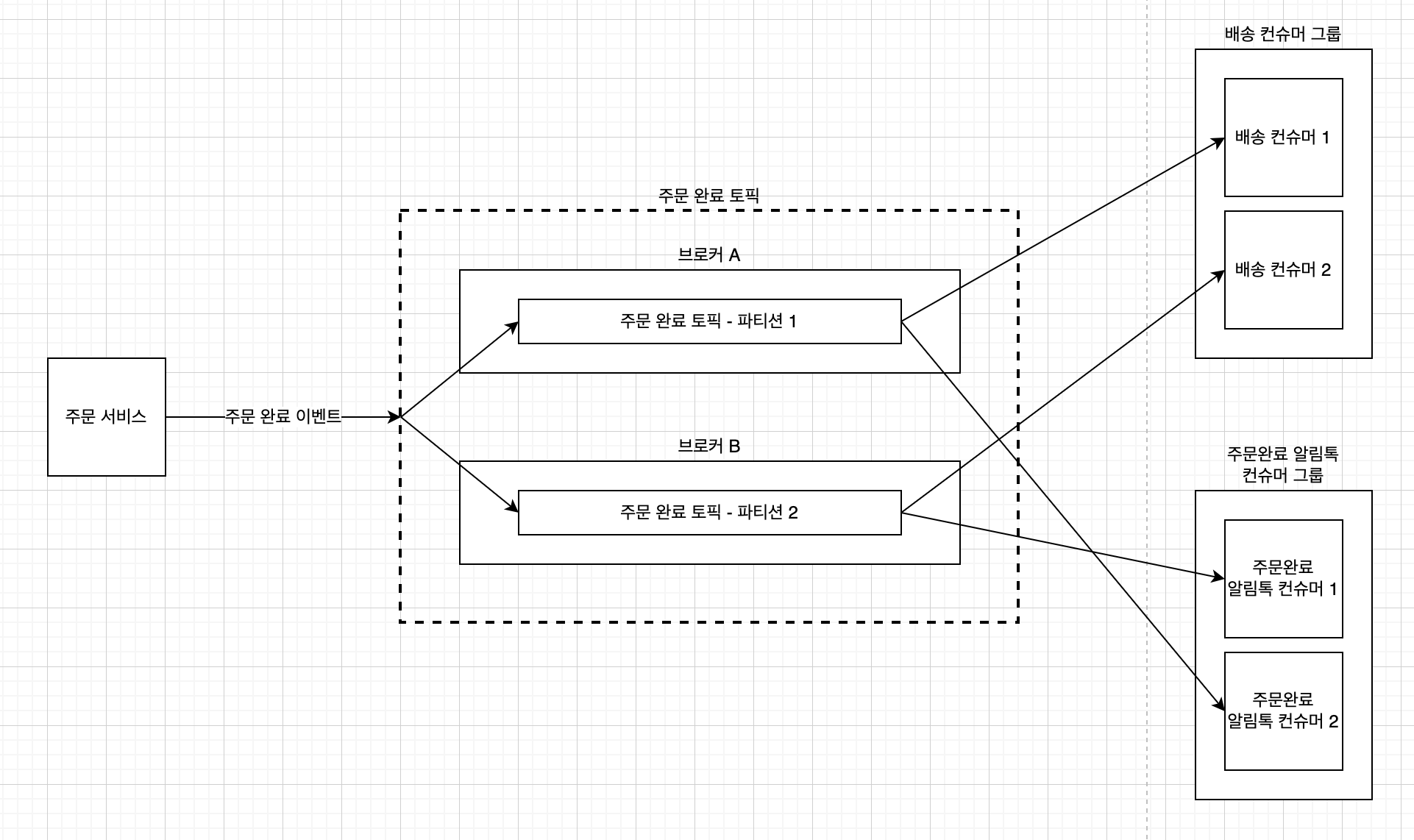
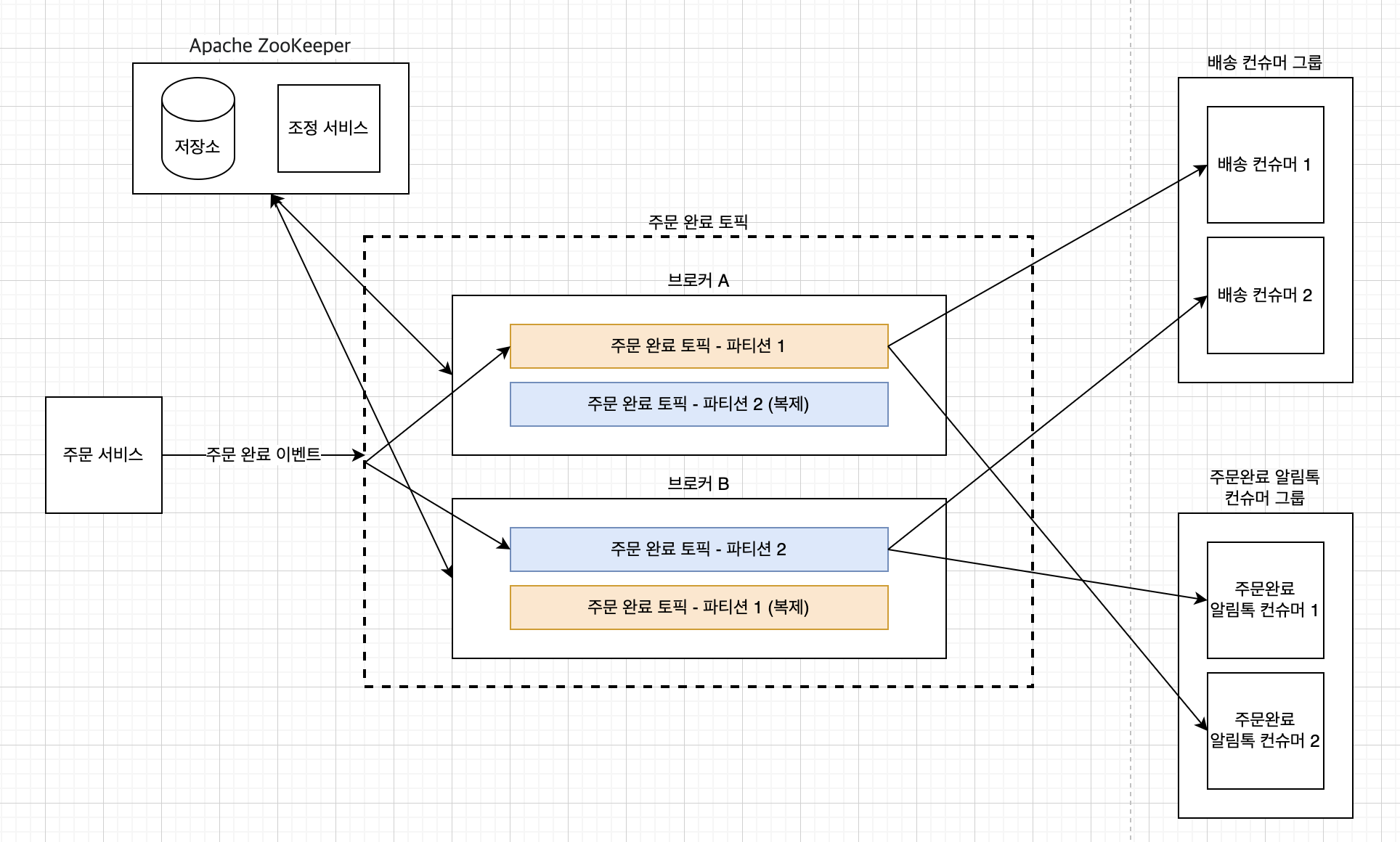
1. 주문 서비스(프로듀서)가 주문완료 이벤트 메시지를 발행합니다.
2. 메시지가 주문완료 토픽에 도착합니다.
3. 토픽에 도착한 메시지는 라운드 로빈 등의 방식으로 파티션에 분배됩니다.
4. 주문완료 토픽을 구독하고 있는 배송 컨슈머와 주문완료 알림톡 컨슈머는 수신 받은 메시지를 처리합니다.
위 이미지와 같이 프로듀서가 토픽에 메시지를 발행하고, 컨슈머 그룹이 토픽(파티션)의 메시지를 구독한다면 요구사항 1~3번을 달성할 수 있습니다.
한 가지 중요하게 생각해볼 것은 브로커가 메시지를 컨슈머에게 보낼 것(푸시 모델)인가 아니면 컨슈머가 브로커에서 가져갈 것(풀 모델) 인지입니다.푸시 모델(RabbitMQ, ActiveMQ)과 풀 모델(Kafka)은 각각 장단점이 있어 요구사항에 적합한 모델 선택이 중요합니다.
발행-구독 모델
https://ko.wikipedia.org/wiki/%EB%B0%9C%ED%96%89-%EA%B5%AC%EB%8F%85_%EB%AA%A8%EB%8D%B8
3. 메시지 순서 보장 고민하기
메시지의 순서는 어떻게 보장할 수 있을까요?
파티션은 FIFO 큐처럼 동작하므로 같은 파티션 안에서는 메시지 순서를 보장할 수 있습니다.
하지만 토픽 관점에서는 순서를 보장할 수 없기 때문에 메시지에 키를 할당해야 합니다.
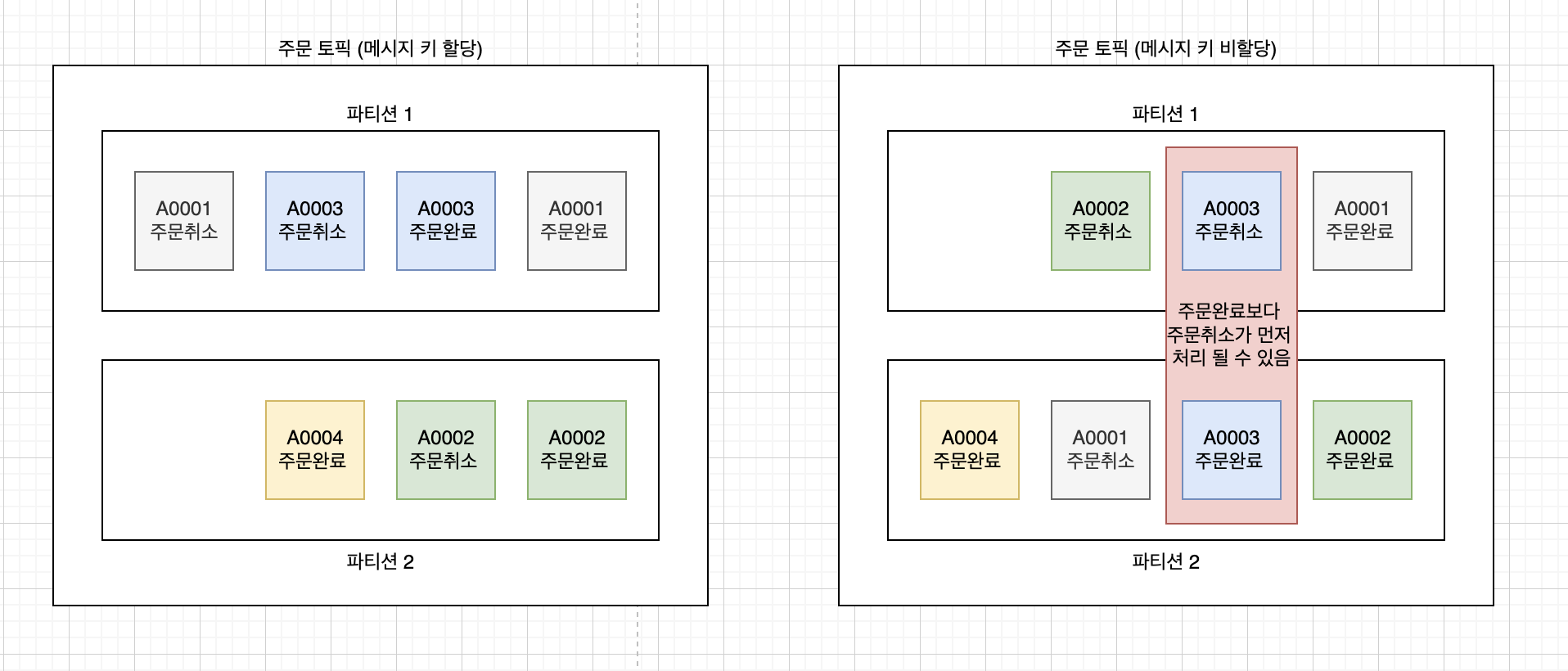
위 이미지처럼 같은 키를 가진 메시지를 같은 파티션으로 보낸다면 키를 가진 메시지는 순서를 보장할 수 있게 됩니다.
물론, 메시지 키를 할당하여도 토픽 관점에서 완벽한 순서 보장은 어렵습니다.
한 스터디원에 따르면, 컨슈머는 메시지를 DB에 적재하고 별도 배치 등으로 DB에 적재 된 데이터를 기준 시간 순으로 정렬하여 처리한 경험을 공유해주셨습니다.
4. 메시지 저장 방식 고민하기
데이터의 장기 보관 요구사항을 만족하면서 높은 대역폭을 제공하려면 데이터 저장소와 적재 방식을 고민해야 합니다.
메시지 큐는 읽기와 쓰기가 대규모로 빈번하게 일어나기 때문에 파일에 저장하는 것이 적합합니다.
책에서는 쓰기 우선 로그(Write-Ahead Log, WAL)을 소개하고 있는데, 새로운 항목이 추가되기만 하는 일반적인 파일 구조입니다.
또한, 파일이 무한정 커질 것을 대비하여 세그먼트 단위로 파일을 분할해야 합니다.
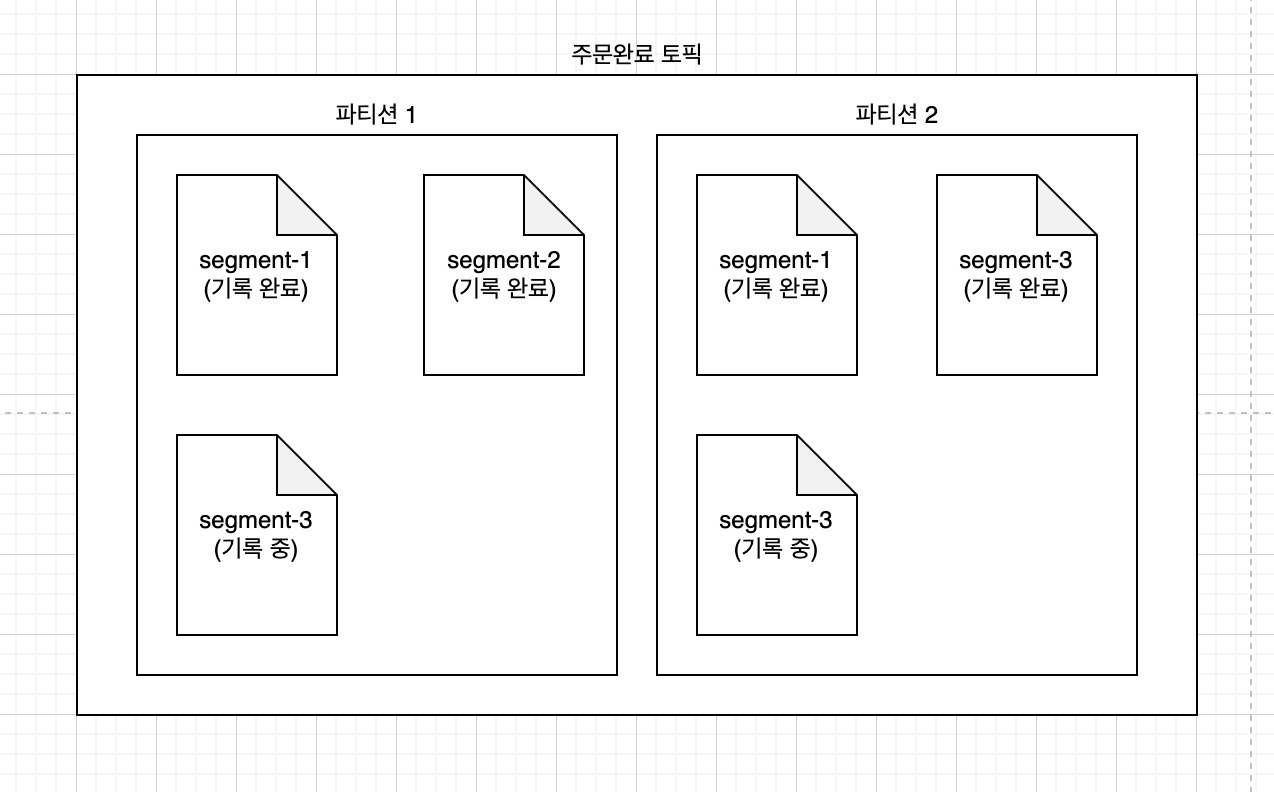
위와 같이 토픽의 파티션 하위에 세그먼트별로 WAL을 관리한다면, 용량 한계에 도달하거나 보관 기간이 만료된 오래된 세그먼트 파일을 삭제할 수 있습니다.
책에서는 회전 디스크 사용과 배치 처리 등 I/O를 줄이는 방법도 소개하고 있습니다.
5. 메타 정보 관리하기
메시지 큐는 내부적으로 다양한 메타 정보를 관리해야 합니다.
- 파티션에 할당된 컨슈머 정보
- 컨슈머가 읽어간 마지막 메시지의 오프셋
- 토픽 설정이나 속성 정보
- 메시지 및 사본 등 기타 정보
위와 같은 정보들은 높은 일관성을 요구하므로 Apache ZooKeeper 같은 키-값 저장소를 고려하는 것이 적합합니다.
또한, 주키퍼는 브로커의 리더 선출 과정을 돕기도 합니다.
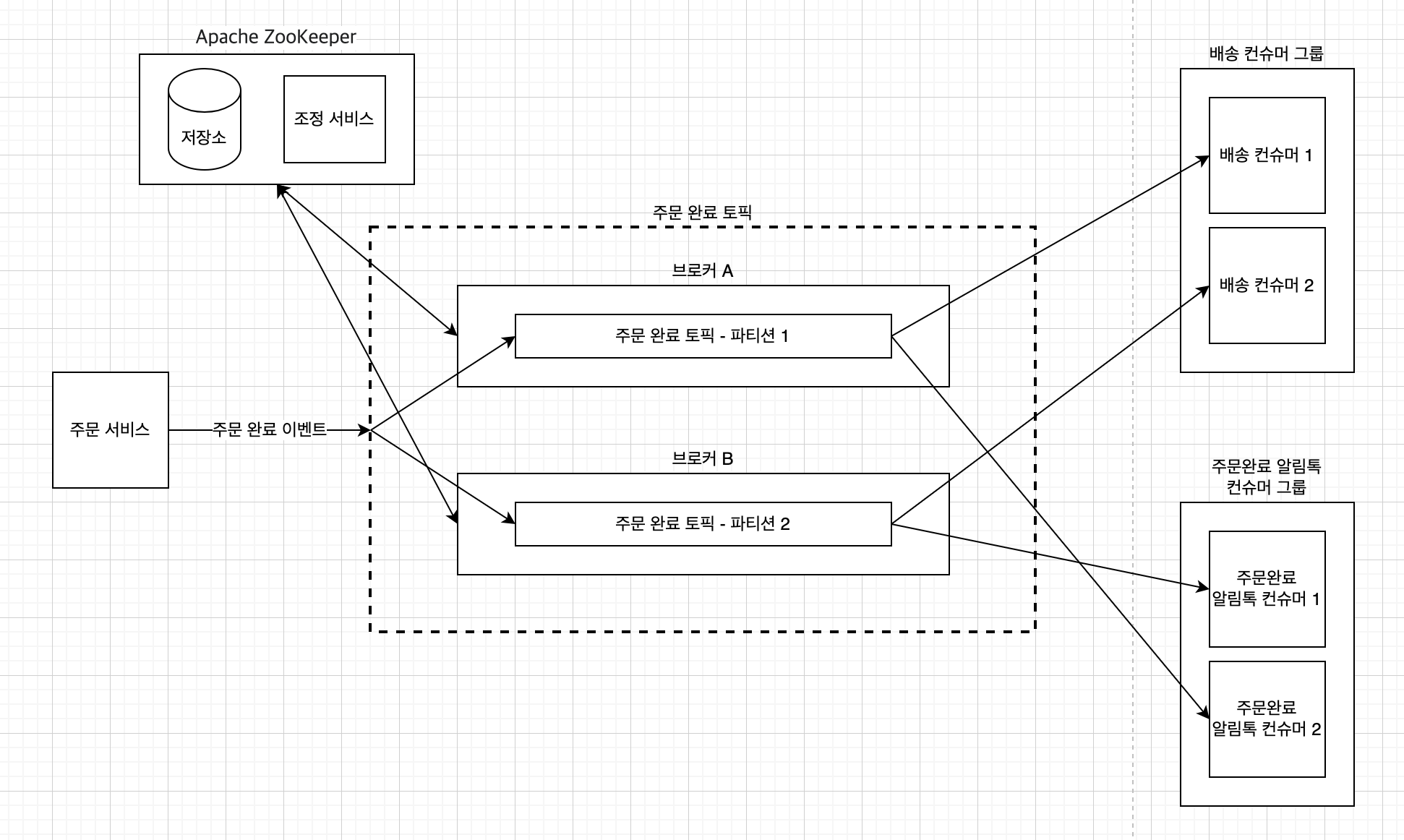
초기 Kafka는 Zookeeper가 자주 죽어서 고생했다는 스터디원의 경험담을 들을 수 있었습니다.
Kafka 버전이 업데이트 될 수록 Zookeeper 안정성은 높아졌지만, Zookeeper로 인한 복잡도 증가 때문에 Kraft 전환 작업을 진행하고 있습니다.
Kraft 릴리즈 내역을 소개한 공식 문서입니다.
KIP-833: Mark KRaft as Production Ready
https://cwiki.apache.org/confluence/display/KAFKA/KIP-833%3A+Mark+KRaft+as+Production+Ready
Kafka가 Zookeeper에서 Kraft로 전환한 이유를 소개한 글입니다.
Kafka’s Shift from ZooKeeper to Kraft
https://www.baeldung.com/kafka-shift-from-zookeeper-to-kraft
6. 데이터 유실 방지하기
분산 시스템에서 하드웨어 장애는 언제든지 발생할 수 있습니다.
데이터 유실을 막고 가용성을 보장하기 위해 복제(Replication)를 제공해야 합니다.
리더 파티션과 사본 파티션이 있으며 리더와 사본은 서로 다른 브로커에 존재합니다.
프로듀서는 리더 파티션에게만 메시지를 발행합니다.
사본 파티션은 리더 파티션을 동기화합니다.
리더 파티션은 사본 파티션의 동기화를 체크하고 프로듀서에 메시지 수신 응답(Ack)을 합니다.
Ack 설정은 메시지큐의 성능과 영속성 사이에서 타협을 해야합니다.
Ack=all- 모든 사본 파티션이 동기화를 해야하므로 메시지 유실 없음
- 느린 응답
- 송금, 주문 등 데이터가 유실되면 안되는 경우
Ack=1- 리더 파티션이 메시지를 저장하고 Ack를 하므로 리더 파티션 장애 발생 시 메시지 유실
- 핫딜 앱 푸시 메시지 같이 일정 부분 유실을 감수하더라도, 대량 처리가 필요한 경우
Ack=0- Ack를 기다리지 않으므로 언제든지 메시지 유실 발생 가능
- 빠른 응답
- 로그, 지표 등 데이터가 유실되도 상관 없는 경우
7. 확장 가능한 시스템 설계하기
메시지 큐는 시스템 특성상 분산 시스템일 수밖에 없습니다.
단기간에 메시지가 급증해도 처리가 가능해야 합니다.
주요 컴포넌트 관점에서 규모 확장성을 어떻게 달성할 수 있을지 생각해봅시다.
프로듀서
메시지를 생산하는 프로듀서는 사용량(트래픽)에 따라 프로듀서를 추가하거나 삭제함으로써 규모 확장성을 달성할 수 있습니다.
컨슈머
메시지 처리량보다 생산량이 많다면, 컨슈머를 추가하여 처리량을 늘려야 합니다.
컨슈머가 추가/삭제되면 리밸런싱이 발생하며, 메시지 큐 설정에 따라 사이드 이펙트가 발생할 수 있으므로 주의해야 합니다.
카프카 컨슈머 리밸런싱을 소개한 여기어때 기술블로그 입니다.
카프카 컨슈머 그룹 리밸런싱 (Kafka Consumer Group Rebalancing)
https://techblog.gccompany.co.kr/%EC%B9%B4%ED%94%84%EC%B9%B4-%EC%BB%A8%EC%8A%88%EB%A8%B8-%EA%B7%B8%EB%A3%B9-%EB%A6%AC%EB%B0%B8%EB%9F%B0%EC%8B%B1-kafka-consumer-group-rebalancing-5d3e3b916c9e
브로커
브로커 내부에는 토픽의 리더 파티션과 사본 파티션이 존재하며, 실제 데이터가 기록된 WAL을 저장하고 있습니다.
따라서 브로커가 추가/삭제될 경우 데이터 유실 없이 사본을 어떻게 분산할지 계획을 세워야 합니다.
파티션
파티션 당 한 개의 컨슈머만 할당될 수 있으므로, 파티션과 컨슈머를 같은 수로 증가시켜야 합니다.
파티션 수 조정은 비용이 큰 작업이므로 트래픽이 없는 시간대에 작업하는게 좋습니다.
또한, 카프카 설정에 따라 메시지가 유실될 수 있으므로 주의해야 합니다.
파티션 증가 시 auto.offset.reset 옵션 때문에 발생할 수 있는 사이드 이팩트와 해결방안을 소개한 블로그입니다.
카프카 컨슈머의 auto.offset.reset 옵션을 반드시 earliest로 변경해야 하는 이유
https://blog.voidmainvoid.net/514
Parallel Consumer를 소개한 네이버 기술블로그입니다.
Kafka에서 파티션 증가 없이 동시 처리량을 늘리는 방법 - Parallel Consumer
https://d2.naver.com/helloworld/7181840
8. 메시지 전송 전략 설계하기
메시지 큐를 사용하면 프로듀서와 컨슈머는 느슨한 결합 구조가 되어 서로 비동기적으로 수행합니다.
따라서 메시지 전송의 신뢰성을 보장해야 하며, 메시지 큐의 성능(신뢰성↓)과 메시지 전송의 신뢰성(성능↓) 사이에서 선택할 수 있도록 메시지 전달 방식을 지원해야 합니다.
일반적으로 메시지 큐는 세 가지 메시지 전달 방식이 있습니다.
최대 한 번 (at-most once)
메시지를 최대 한 번만 전달하는 방식입니다.
메시지가 전달 과정에서 소실되어도 다시 전달되는 일은 없습니다.
프로듀서는 Ack=0 설정으로 메시지를 발행하고 수신응답을 기다리지 않습니다.
메시지 전달이 실패해도 다시 시도하지 않습니다.
컨슈머는 메시지를 읽고 처리하기 전에 오프셋부터 갱신합니다.
메시지를 처리하기 전에 오프셋을 갱신하므로 처리 과정에서 장애/오류가 발생할 경우, 해당 메시지를 다시 소비할 수 없습니다.
최소 한 번 (at-least once)
같은 메시지가 한 번 이상 전달될 수 있습니다.
메시지 소실이 발생하지 않습니다.
프로듀서는 Ack=1 또는 Ack=all 설정으로 메시지를 발행하고, 메시지가 브로커에 정상적으로 전달되었는지 반드시 확인합니다.
메세지 전달이 실패하거나 타임아웃이 발생한 경우에는 계속 재시도 합니다.
컨슈머는 메시지를 정상적으로 처리하고 오프셋을 갱신합니다.
메시지 처리 과정에서 장애/오류가 발생하여도 해당 메시지를 다시 소비합니다.
단, 메시지를 정상적으로 처리했으나 오프셋 갱신에 실패하면 중복 처리될 수 있으므로 컨슈머가 멱등적으로 처리할 수 있도록 구성해야 합니다.
정확히 한 번 (exactly once)
정확히 한 번 (exactly once)는 프로듀서와 컨슈머 모두 멱등성을 보장해야 하는 구현이 가장 까다로운 방식입니다.
메세지는 정확히 한 번 전달 되며 메시지 소실이 발생하지 않습니다.
Kafka 기준으로 프로듀서는 Ack=all과 idempotence=true, transactional.id=my-tx-id 설정으로 메시지의 유일성을 보장하여 발행합니다.
메시지 큐만으로 정확히 한 번을 보장하기 어렵다면, InBox OutBox 패턴으로 도움을 줄 수 있습니다.
정확히 한 번 (exactly once)은 스터디원 분들과 가장 많은 얘기를 나눌정도로 실제로 가능한 개념인지 의견이 분분했습니다.
본 포스팅을 작성하기 위한 구글링 과정에서도 관련 내용으로 토론하는 게시물들을 꽤 볼 수 있었으며, 비현실적이다. 불가능하다. 라는 의견이 달리기도 했습니다.
모든 것은 트레이드 오프를 동반하므로 정확히 한 번 (exactly once)을 달성하기 위해 값 비싼 비용을 지불해야할지 고민하는게 중요할 것 같습니다.
아파치 카프카 Exactly-once 처리의 진실과 거짓
https://blog.voidmainvoid.net/504
Kafka가 exactly once를 어떻게 달성하는지 소개하는 글입니다.
Exactly-Once Semantics Are Possible: Here’s How Kafka Does It
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
Inbox, Outbox 패턴을 소개하는 글입니다.
Overcoming Message Delivery Challenges in Distributed Systems: A Comprehensive Look at Outbox and Inbox Patterns
https://medium.com/hprog99/overcoming-message-delivery-challenges-in-distributed-systems-a-comprehensive-look-at-outbox-and-a669e5f21898
일 3,000만 건의 네이버페이 주문 메시지를 처리하는 Kafka 시스템의 무중단 전환 사례
https://d2.naver.com/helloworld/9581727