
실시간 게임 순위표
이번 글에서는 가상 면접 사례로 배우는 대규모 시스템 설계 기초 2 10장 실시간 게임 순위표를 소개하려고 합니다.
실시간 게임 순위표의 특징을 간단히 알아보고, 기본적인 요소를 설계해봅시다.
1. 실시간 게임 순위표 이해 및 설계 범위 확정하기
실시간 게임 순위표는 꽤 간단한 시스템으로 보입니다.
하지만, 복잡성을 더할 수 있는 여러 가지 문제가 있으므로 요구사항(특징)을 분명히 확인하는게 좋습니다.
1. 사용자는 경기에서 승리하면 포인트를 얻습니다.
2. 모든 플레이어가 순위표에 포함되어야 합니다.
3. 매달 새로운 토너먼트가 시작할 때마다 새로운 순위표를 만듭니다.
4. 상위 10명의 사용자와 특정 사용자의 순위를 순위표에 표시할 수 있어야 합니다.
5. DAU 500만 명, MAU 2,500만 명으로 가정합니다.
6. 플레이어는 하루 평균 10경기를 치룹니다.
7. 두 플레이어의 점수가 같을 경우 순위는 동일합니다.
8. 순위표는 실시간이어야 합니다.
ZDNET 배달앱 상반기 MAU, 1년새 470만 줄었다 기사에 의하면 2023년 6월 배달앱(배달의민족과 요기요, 쿠팡이츠)의 MAU가 2,900만이라고 합니다.
따라서, 요구사항으로 제시된 DAU 500만 명과 MAU 2,500만 명이라는 수치에 주의하여 시스템을 설계할 필요가 있습니다.
DAU 500만 명인 게임에서 플레이어가 24시간 동안 고르게 분포한다면, 초당 평균 50명의 플레이어가 게임에 참여한다는 계산이 나옵니다.500만 DAU / 10^5초(86400) =~ 50
하지만 게임 서비스 특성상 트래픽은 균등하지 않고, 저녁 시간에 집중될 가능성이 높습니다.
이를 고려하여 최대 부하를 5배라고 가정하면 초당 250명의 플레이어를 감당할 수 있어야 합니다.
플레이어는 하루 평균 10경기를 치룬다고 가정하였으므로 점수 획득 이벤트는 평균 500QPS (50 x 10), 최대 2,500QPS (50 x 10 x 5)입니다.
2. 개략적 설계안 제시하기
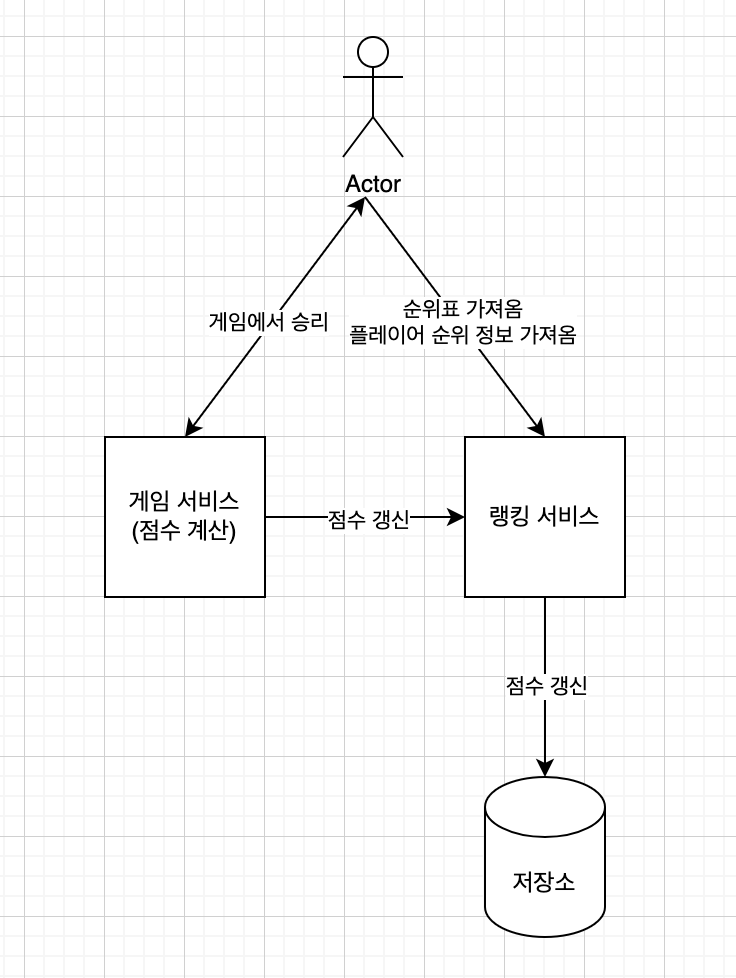
개략적인 설계안 입니다.
플레이어(단말)은 게임 승리 시 게임 서비스를 호출합니다.
게임 서비스는 플레이어의 점수를 계산하고, 랭킹 서비스를 호출합니다.
랭킹 서비스는 플레이어의 점수를 갱신합니다.
요구사항에 따라 메시지 큐를 도입하는 등 서비스 구성을 다르게 설계할 수 있습니다.
게임 순위표 시스템에서 가장 중요한 것은 반드시 서버에서 점수 계산을 수행해야한다는 점입니다.
클라이언트는 중간자 공격과 같은 보안상 문제로 점수 계산을 하기에 적합하지 않습니다.
중간자 공격(man in the middle attack, MITM)
https://ko.wikipedia.org/wiki/%EC%A4%91%EA%B0%84%EC%9E%90_%EA%B3%B5%EA%B2%A9
3. 정렬 집합(Sorted Set)
DAU 500만 명인 게임에서 플레이어의 순위를 효과적으로 가져오기 위해서는 정렬 집합(Sorted Set)이 가장 좋은 해결책이 될 수 있습니다.
정렬 집합은 내부적으로 해시 테이블과 스킵 리스트라는 두 가지 자료 구조를 사용합니다.
해시 테이블은 사용자의 점수를 저장하기 위함이고, 스킵 리스트는 특정 점수 가진 사용자들의 목록을 저장하기 위해 쓰입니다.
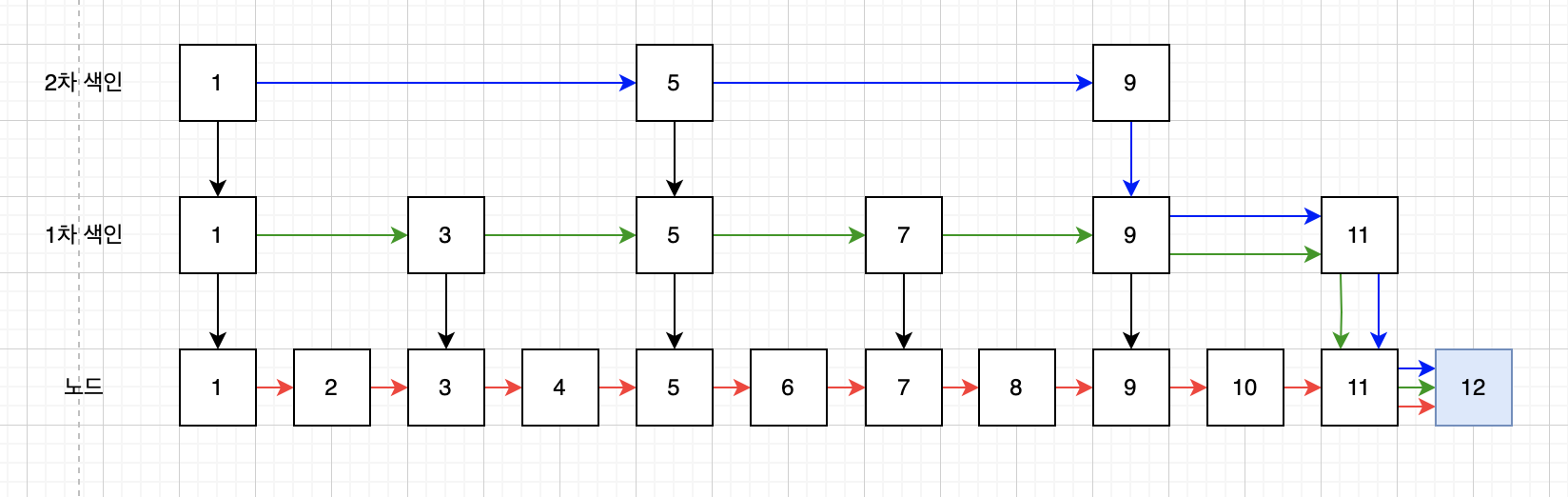
위 이미지에서 12번 노드를 찾는다고 가정해 봅시다.
정렬집합은 중간 노드를 건너뛰는 N차 색인이 존재합니다.
빨간색 화살표: 11번째에 도착
초록색 화살표(1차 색인): 7번째에 도착
파란색 화살표(2차 색인): 6번만에 도착
이 처럼 다단계 색인을 사용하면 원하는 노드를 훨씬 빠르게 검색할 수 있으며, 전체 노드가 많아질 수록 효과는 증가합니다.
4. Redis
실시간 순위표에 적합한 저장소를 알아보겠습니다.
RDB는 가장 간단한 방안이지만, 수 백만 ~ 수 천만명의 플레이어가 존재할 경우 성능은 급격히 떨어집니다.
Index와 Limit를 추가하여도 정확한 순위를 알아내려면 테이블의 전체 데이터를 조회해야하는 문제가 있습니다.
또한, 점수가 지속적으로 변경되기 때문에 DB 캐시를 사용할 수 없으므로 실시간 게임 순위를 구현하기에 적합하지 않습니다.
Redis는 메모리 기반 key-value 저장소입니다.
메모리에서 동작하므로 빠른 읽기와 쓰기가 가능하고, 정렬 집합 자료형을 제공하기 때문에 실시간 순위표 저장소로 적합합니다.
책에서는 Redis 명령어를 자세하게 소개하고 있지만, 여기서는 링크로 대체하겠습니다.
- ZADD (신규 플레이어 추가): https://redis.io/commands/zadd/
- ZINCRBY (점수 갱신): https://redis.io/commands/zincrby/
- ZRANGE (상위 10명 조회): https://redis.io/commands/zrange/
- ZREVRANK (플레이어 랭킹 조회): https://redis.io/commands/zrevrank/
Redis는 싱글 스레드로 동작하기 때문에 O(N) 명령어는 주의해서 사용해야 합니다.
Redis를 사용할 경우 데이터의 영속성을 고민해야 합니다.
Redis도 데이터를 디스크에 영구적으로 보관할 수 있지만, Redis 인스턴스가 재시작하는 등이 발생할 경우 준비 시간이 많이 걸립니다.
따라서 Master - Slave로 구성하여 장애에 대응할 수 있도록 해야합니다.
500만 DAU 정도라면 한 대의 Redis로도 충분히 처리할 수 있지만, 사용량이 늘어나면 Redis의 샤딩을 고려해야 합니다.
게임 순위표에 적합한 샤딩 방식은 고정 파티션과 해시 파티션 방식이 있습니다.
고정 파티션은 순위표에 등장하는 점수 범위에 따라 파티션을 나누는 방식입니다.
예를 들어 토너먼트에서 획득할 수 있는 점수 범위가 1(최소) ~ 1000(최대)인 경우, 10개의 샤드를 두고 각 샤드는 100만큼의 범위를 처리하는 방안입니다.
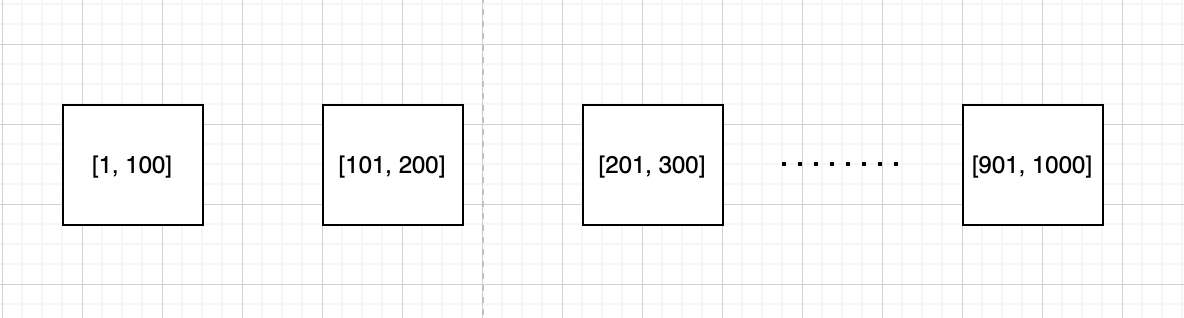
이 기능이 제대로 작동하려면 순위표 전반에 점수가 고르게 분포되야 합니다.
따라서 핫스팟 샤드가 발생하지 않도록 샤드에 할당된 점수 범위를 조정해야 합니다.
사용자의 점수가 높아져서 다른 샤드로 옮길 경우, 기존 샤드에서 데이터를 제거한 다음 새 샤드로 옮겨야 합니다.
901 ~ 1000 점수 범위를 처리하는 샤드에서 상위 10명의 플레이어 정보를 쉽게 가져올 수 있습니다.
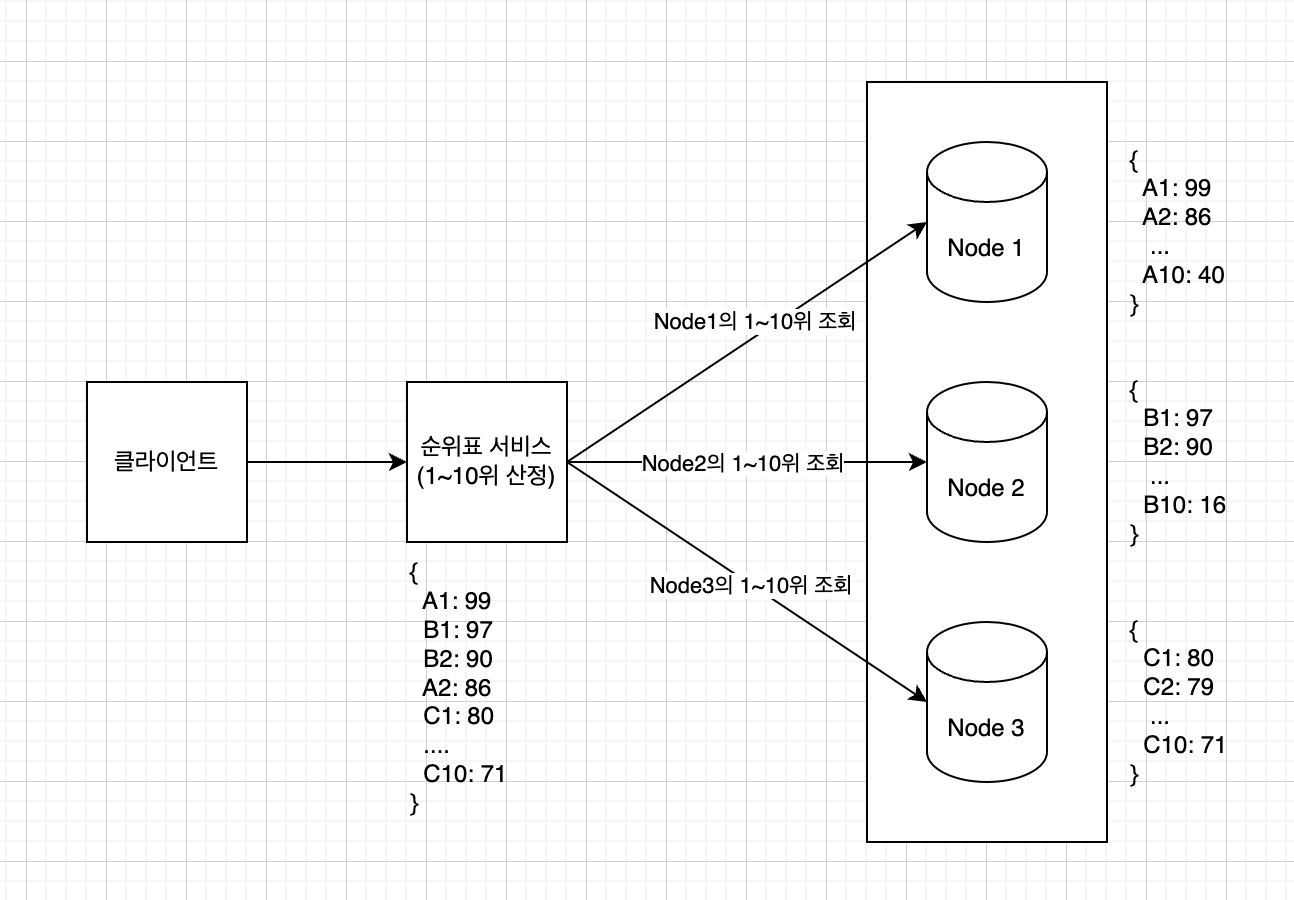
해시 파티션은 Redis 클러스터를 사용하는 것으로 핫스팟 문제를 쉽게 해결할 수 있습니다.
Redis 클러스터는 여러 노드에 데이터를 자동으로 샤딩해줍니다.
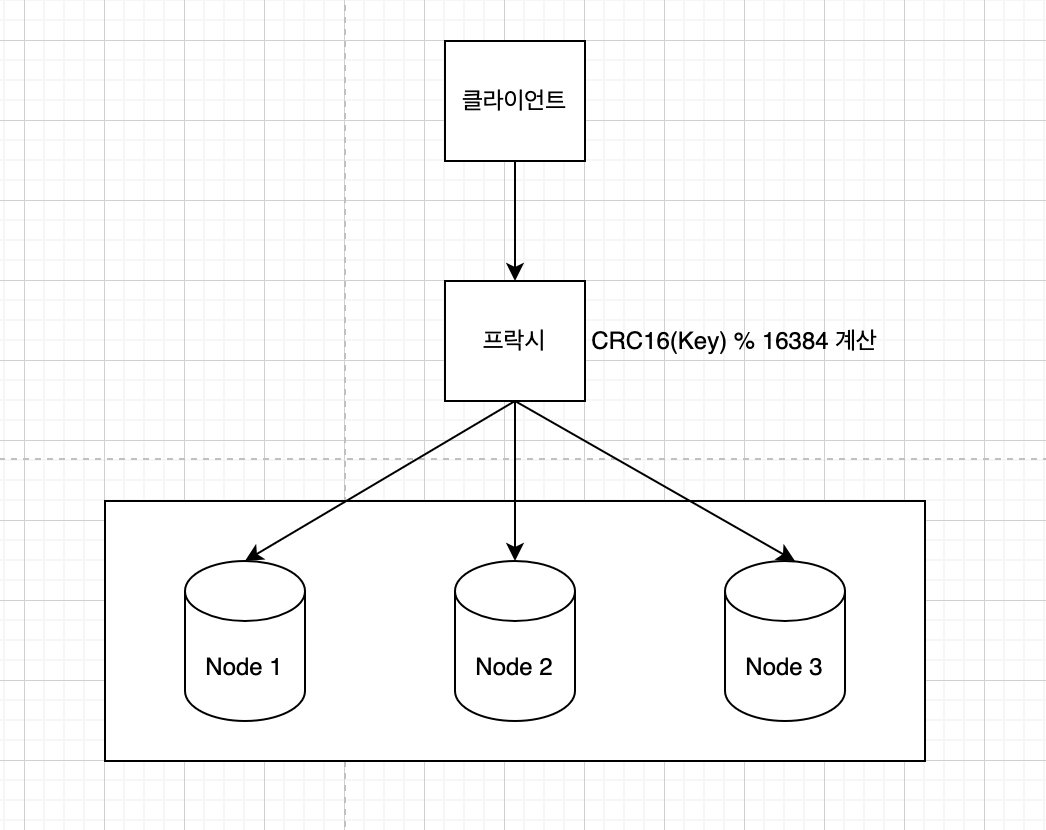
CRC16(Key) % 16384 연산을 수행하여 Key(플레이어)를 찾아 점수를 갱신하면 됩니다.
💡 CRC16(Key) % 16384 계산식에서 16384(16K)의 의미
(Redis Github과 Stackoverflow를 참고하여 작성한 것으로 실제 내용과 차이가 있을 수 있습니다.)CRC16은 2^16 -1 = 65535로 65K까지 정의할 수 있습니다.
멱등적으로 사용하려면 65K 슬롯과 16K 슬롯 두 가지 선택지가 있습니다.65K 슬롯은 8K Bitmap Size(8 * 8 (8 bit/byte) * 1024(1k))의 네트워크 비용을 사용합니다.
반면, 16K 슬롯은 2K 네트워크 비용을 사용합니다.현실적으로 레디스 마스터 노드를 1000개 이상 사용할 경우가 없으므로, 16K 슬롯으로 제한하여 네트워크 비용을 줄입니다.
상위 10명의 플레이어 정보는 모든 Node에서 상위 10명의 플레이어를 조회한 다음 애플리케이션 내에서 다시 정렬하는 분산-수집 접근법을 사용해야 합니다.
따라서 특정 Node가 응답이 느릴 경우 서비스 지연이 발생하게 됩니다.
책에서는 Redis 파티션의 대안으로 NoSQL(DynamoDB, 카산드라, MongoDB)을 제안하고 있습니다.
Redis의 기본 개념과 샤딩, 운영시 장애 포인트를 상세하게 설명해주는 좋은 영상입니다.
[우아한테크세미나] 191121 우아한레디스 by 강대명님
https://youtu.be/mPB2CZiAkKM