대규모 광고 클릭 이벤트 집계 시스템 설계
디지털 광고 시장에서 RTB(Real Time Bidding)는 필수적인 프로세스입니다. 이를 통해 광고주는 실시간으로 광고 지면(inventory)을 거래하며, 이 과정에서 발생하는 광고 클릭 데이터의 정확한 집계는 매우 중요합니다. 본 문서에서는 페이스북이나 구글과 같은 대형 플랫폼에 적합한 광고 클릭 이벤트 집계 시스템의 설계 방안을 제안합니다.
광고 클릭 이벤트 집계 시스템과 디지털 광고 생태계의 상호작용
디지털 광고 생태계에서, 광고 클릭 이벤트 집계 시스템은 다양한 플레이어들과 상호작용합니다. 주요 엔터티로는 DSP(광고주 측에서 광고를 올리는 플랫폼), SSP(다양한 인벤토리를 판매할 수 있는 플랫폼), 그리고 광고 거래소가 있습니다. 이들 간의 거래는 OPEN RTB라는 규격화된 스펙을 통해 이루어집니다.
DSP (Demand-Side Platform): DSP는 광고주들이 자신의 광고 캠페인을 관리하고, 적절한 광고 지면을 구매할 수 있는 플랫폼입니다. 이 플랫폼은 다양한 광고 크기와 포맷을 지원하며, 광고의 구매와 판매가 이루어지는 곳입니다.
SSP (Supply-Side Platform): SSP는 웹사이트 소유자나 퍼블리셔들이 자신의 디지털 인벤토리를 판매할 수 있는 플랫폼입니다. 이 플랫폼을 통해 퍼블리셔들은 다양한 광고 네트워크와 광고 거래소에 접근할 수 있습니다.
OPEN RTB: 이는 Real-Time Bidding(실시간 입찰)을 위한 업계 표준 프로토콜입니다. DSP와 SSP 사이에서 광고 인벤토리의 구매 및 판매가 실시간으로 이루어지며, 이 과정에서 광고 클릭 이벤트 데이터가 생성됩니다.
국내외 주요 AD tech 기업

광고 클릭 이벤트 집계 시스템은 이러한 데이터를 처리하고, 광고 클릭 이벤트의 수, 광고별 성능, 광고주와 퍼블리셔 간의 거래를 분석하는 데 중요한 역할을 합니다. 이 시스템은 또한 클릭 어뷰징 검증, 광고 고유키와 인벤토리 ID의 관리, 다양한 보고서 제공 등을 수행함으로써, 디지털 광고 생태계에서 투명성과 효율성을 높이는 데 기여합니다.
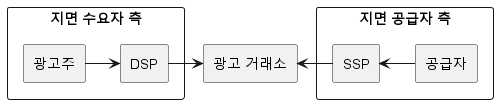
우리는 여기서 SSP의 클릭 이벤트를 집계하여 DSP와 광고 거래소에 정보를 제공하는 플랫폼을 설계해보겠습니다.
설계의 시작: 문제 파악과 범위 정의
광고 클릭 이벤트 데이터는 다양한 서버에 분산되어 로그 파일 형태로 존재합니다. 일일 클릭 수는 약 10억 건에 달하며, 광고 게재 횟수는 200만 회에 이릅니다. 이 데이터량은 매년 약 30%씩 증가하는 추세입니다. 우리 시스템은 다음과 같은 질의를 지원해야 합니다:
- 특정 광고(ad_id)의 최근 M분간 클릭 수 집계
- 최근 1분간 가장 많이 클릭된 상위 100개 광고의 아이디 반환
- ip, user_id, country 등 다양한 속성으로 이러한 질의 결과를 필터링
또한, 시스템은 늦게 도착하는 데이터, 중복 이벤트, 시스템 복구 등에 대한 처리를 고려해야 하며, 모든 처리는 수 분 내에 완료되어야 합니다.
기능 요구사항
시스템은 다음 기능을 수행할 수 있어야 합니다:
- 시간 기반 클릭 수 집계: 특정 광고에 대한 지정된 시간 동안의 클릭 수를 집계합니다.
- 상위 클릭 광고 식별: 가장 높은 클릭 수를 기록한 상위 100개 광고를 식별합니다.
- 필터링 기능: 집계 결과를 다양한 속성(ip, user_id, country)에 따라 필터링할 수 있어야 합니다.
비기능 요구사항
시스템 설계는 다음 비기능 요구사항을 충족해야 합니다:
- 정확성: 집계 결과의 정확성은 매우 중요합니다, 데이터는 RTB 및 광고 과금에 사용됩니다.
- 이벤트 처리: 지연되거나 중복된 이벤트를 효과적으로 처리할 수 있어야 합니다.
- 신뢰성: 시스템은 부분적인 장애를 견딜 수 있어야 합니다.
- 응답 시간: 전체 처리 시간은 몇 분을 넘지 않아야 합니다.
데이터 추정 및 처리 요구사항
- 일일 활성 사용자(DAU): 10억
- 일일 클릭 수: 사용자당 평균 1개 광고 클릭
- 초당 질의 수(QPS): 10,000 (일일 클릭 수를 86400초로 나눈 값)
- 최대 QPS: 기본 QPS의 5배인 50,000으로 가정
- 데이터 크기: 클릭 이벤트 하나의 크기를 0.1KB로 가정할 때, 일일 데이터는 약 100GB, 월간 데이터는 3TB에 이릅니다.
이 설계 제안은 페이스북이나 구글과 같은 대규모 플랫폼에서 필요로 하는 광고 클릭 이벤트 집계 시스템의 기본 틀을 제시합니다. 실제 구현 시에는 분산 시스템 설계, 데이터 파이프라인 최적화, 실시간 데이터 처리 등의 다양한 고급 기술이 필요할 것입니다. 그러면 이제 함께 차근차근 만들어 보겠습니다.
개략적 설계안
질의 API 설계
대규모 광고 클릭 이벤트 집계 시스템에서는 다양한 사용자가 데이터에 접근해야 합니다. 이들은 대시보드를 통해 광고 데이터를 분석하는 데이터 과학자, 제품 관리자, 광고주들입니다. 이들의 요구사항을 충족시키기 위해, 다음과 같은 API를 설계했습니다.
API 1: 지난 M분간 각 ad_id에 발생한 클릭 수 집계
이 API는 특정 광고(ad_id)에 대한 지정된 기간 동안의 클릭 수를 집계합니다.
GET /v1/ads/{:ad_id}/aggregated_count
파라미터:
- from: 집계 시작 시간
- to: 집계 종료 시간
- filter: 필터링 전략 (예: country, user_id 등)
응답:
{
"ad_id": "ad_id",
"count": 123
}
API 2: 지난 M분간 가장 많이 클릭된 상위 광고 반환
이 API는 지정된 시간 동안 가장 많이 클릭된 광고들을 반환합니다.
GET /v1/ads/popular_ads
파라미터:
- count: 반환할 상위 광고의 수
- window: 집계 기간 (분 단위)
- filter: 필터링 전략
응답:
{
"ad_ids": ["id1", "id2", "id3"]
}
데이터 모델 설계
이 시스템은 크게 두 가지 유형의 데이터를 다룹니다: 원본(raw) 데이터와 집계(aggregated) 데이터.
원본 데이터 (Raw Data)
- 장점: 모든 원본 데이터를 보존하며, 필요시 언제든지 데이터를 필터링하고 재계산할 수 있습니다.
- 단점: 엄청난 양의 데이터를 저장해야 하므로, 저장 공간을 많이 차지하며, 데이터 조회 성능이 떨어질 수 있습니다.
집계 데이터 (Aggregated Data)
- 장점: 데이터를 사전에 집계하여 저장함으로써, 빠른 질의 응답 시간을 보장하고 저장 공간을 절약할 수 있습니다.
- 단점: 집계 과정에서 일부 데이터가 손실될 수 있으며, 나중에 다른 기준으로 데이터를 재집계하기 어려울 수 있습니다. 두 유형의 데이터를 모두 저장함으로써, 시스템은 유연성을 유지하고, 필요시 원본 데이터를 기반으로 추가 분석을 수행할 수 있습니다. 원본 데이터는 주로 시스템 문제 해결과 디버깅에 사용되며, 집계 데이터는 일반적인 질의 응답에 활용됩니다. 이러한 설계는 시스템의 성능과 정확성을 동시에 보장합니다.
올바른 데이터베이스의 선택
광고 클릭 이벤트 집계 시스템에서 데이터의 관리 및 처리는 중요한 부분입니다. 데이터의 특성을 고려할 때, raw data와 aggregated data 모두 고려해야 할 요소가 있습니다.
Raw Data
- 특성: 대부분 쓰기 작업이며, 데이터의 양이 방대합니다.
- 저장 방안:
- 쓰기에 최적화된 데이터베이스 사용: 쓰기 작업이 주를 이루기 때문에, 쓰기 작업에 유리한 데이터베이스인 Cassandra나 InfluxDB가 적합할 수 있습니다.
- Blob Storage 활용: AWS S3 같은 blob storage에 데이터를 저장하는 방법도 효율적입니다. ORC, Parquet, AVRO 같은 형식으로 데이터를 저장하면, 데이터의 압축과 최적화가 가능해져 대규모 데이터를 효율적으로 관리할 수 있습니다.
Aggregated Data
- 특성: 쓰기와 읽기 작업이 모두 빈번하게 발생합니다.
- 저장 방안: Aggregated data는 질의 성능을 고려하여, 읽기와 쓰기 성능이 균형 잡힌 데이터베이스에 저장하는 것이 중요합니다. SQL 기반의 데이터베이스나 NoSQL 데이터베이스 중 적합한 솔루션을 선택할 수 있으며, 데이터의 사용 패턴에 따라 적합한 기술을 선택해야 합니다.
비동기 처리의 필요성
동기식 처리 시스템은 예기치 못한 트래픽 증가에 취약하여 전체 시스템의 장애로 이어질 수 있습니다. 이를 방지하기 위해, Kafka와 같은 메시지 큐를 도입하여 생산자와 소비자 간의 결합을 끊어 비동기 처리를 할 수 있습니다. 이는 시스템의 확장성과 안정성을 크게 향상시킬 수 있습니다.
집계 서비스의 설계
집계 서비스는 광고 클릭 이벤트의 집계를 담당하는 핵심 컴포넌트입니다. 맵리듀스 프레임워크는 대규모 데이터를 처리하는데 적합한 방안 중 하나입니다. Hadoop 기반의 맵리듀스는 대규모 데이터셋에 대한 복잡한 연산을 수행할 수 있으나, Java로 프로그램을 개발해야 한다는 단점이 있습니다. 이러한 복잡성을 해소하기 위해 Hive, Presto, Spark 같은 기술이 개발되었습니다. 이들 기술은 각각의 특성과 장단점을 가지고 있으며, 사용 사례에 따라 적합한 기술을 선택할 수 있습니다.
사용 사례에 따른 집계 방안
- 클릭 이벤트 수 집계: map node에서 ad_id 기준으로 이벤트를 분배하고, reduce node에서 최종적으로 집계합니다.
- 가장 많이 클릭된 N개의 ad_id 집계: map node에서 각 ad_id의 클릭 수를 집계하고, 이를 reduce node로 보내 최종적으로 상위 N개를 선정합니다.
- 데이터 필터링: 클릭 이벤트 데이터에 추가적인 차원(예: country)을 도입하여 필터링할 수 있습니다.
Aggregated Data
- 특성: 쓰기와 읽기 작업이 모두 빈번하게 발생합니다. 이는 데이터 집계와 질의 응답에 있어 신속한 처리가 필요함을 의미합니다.
개략적 설계안

비동기 처리의 중요성
동기식 처리 방식은 예기치 않은 트래픽 증가시 전체 시스템의 장애로 이어질 수 있습니다. 이를 방지하기 위해, Kafka와 같은 메시지 큐를 도입하여 생산자와 소비자 간의 결합을 줄이는 것이 좋습니다. 이 방식은 시스템의 확장성과 유연성을 향상시킵니다.
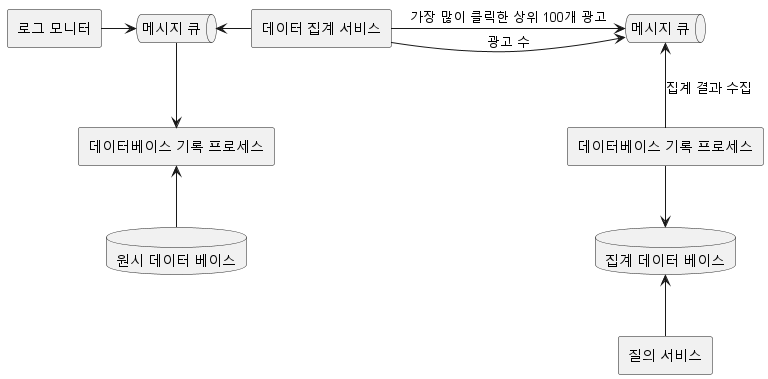
메시지 큐의 역할
메시지 큐는 데이터 처리 과정에서 중간 단계의 데이터를 임시로 저장하며, 다음 처리 단계로의 데이터 전송을 조율합니다. 이를 통해, 시스템 각 부분의 부하를 관리하고, 데이터 처리의 안정성을 높일 수 있습니다.
데이터 집계 서비스
데이터 집계 작업은 맵리듀스 프레임워크를 활용하여 효율적으로 수행할 수 있습니다. Hadoop과 같은 시스템에서 맵리듀스 작업을 수행하거나, Presto나 Spark와 같은 메모리 기반의 쿼리 시스템을 사용하여 데이터 처리 속도를 개선할 수 있습니다.
집계 작업 사례
사례 1: 클릭 이벤트 수 집계
- 방법: Map node에서 ad_id를 기준으로 이벤트를 분배하고, Reduce node에서 이를 집계합니다.
사례 2: 가장 많이 클릭된 광고 집계
- 방법: Map node에서 데이터를 Reduce node로 전송하여 집계하고, 다시 한 번 Reduce 작업을 통해 상위 N개의 광고를 선정합니다.
사례 3: 데이터 필터링
- 방법: 필요한 필터링 차원(예: 국가)을 추가하여 데이터를 필터링합니다. 이는 스타 스키마 방식으로 구성할 수 있으며, 이해하기 쉽고 구축하기 편리하지만, 정규화되지 않아 데이터 중복이 발생할 수 있습니다.
| ad_id | click_minute | country | count |
|---|---|---|---|
| ad001 | 2024010101001 | USA | 100 |
| ad001 | 2024010101001 | GPB | 1200 |
| ad001 | 2024010101001 | others | 1100 |
| ad002 | 2024010101001 | USA | 100 |
이러한 설계안은 대규모 데이터를 효율적으로 처리하고, 다양한 질의에 신속하게 대응할 수 있는 광고 클릭 이벤트 집계 시스템을 구축하는 데 기초를 제공합니다.
3단계: 상세 설계
상세 설계 단계에서는 시스템의 핵심 구성 요소와 그 작동 방식을 구체화합니다. 이 단계에서는 데이터 처리 방식, 데이터 정확성 보장, 그리고 중복 및 지연 처리 등의 복잡한 문제를 해결하는 방법을 포함합니다.
스트리밍 vs 일괄 처리
- Lambda 아키텍처: 스트리밍 처리와 배치 처리를 병행하여 처리하는 구조로, 두 가지 처리 경로를 모두 유지하는 단점이 있습니다.
- Kappa 아키텍처: 배치 처리와 스트리밍 처리 경로를 하나로 통합해 두 경로의 유지 관리 문제를 해결합니다. Kappa 아키텍처는 일괄 처리를 스트리밍 처리로 변환하여 단일 처리 경로를 제공합니다.
- 준호님이 추천해주신 labmda와 kappa 아키텍처 이해에 좋은 영상
데이터 재계산
- Historical Data Replay: 집계 서비스에 버그가 발견되었을 때, 이전 데이터를 다시 처리하여 정확한 집계 결과를 얻기 위한 방법입니다. 이를 위해 데이터는 재처리 가능한 형태로 저장되어야 합니다.
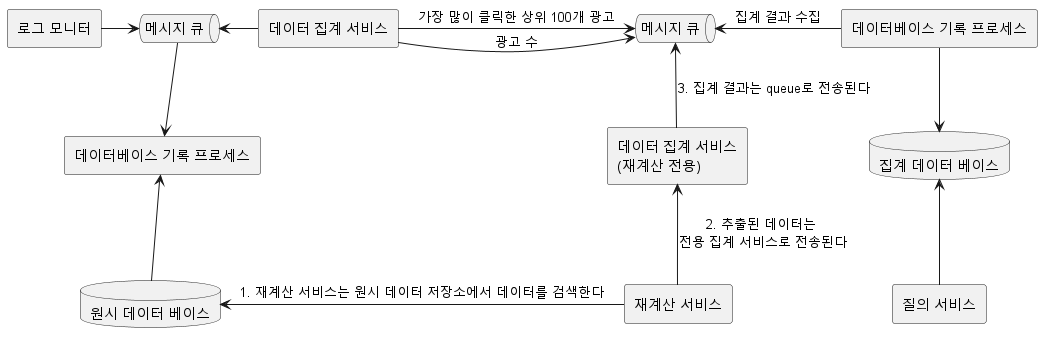
시간 처리
- 이벤트 시각 vs 처리 시각: 이벤트 시각은 광고 클릭이 발생한 시각이고, 처리 시각은 이벤트가 집계 시스템에 의해 처리된 시스템 시각입니다. 네트워크 지연과 비동기 처리 환경 때문에 이 두 시각 사이에 차이가 발생할 수 있습니다. 시스템 설계에서는 이벤트 발생 시각을 기준으로 집계를 수행하는 것이 일반적입니다.
| 장점 | 단점 | |
|---|---|---|
| 이벤트 발생 시각 | 집계 결과가 정확하다 | 클라이언트의 시간에 의존하므로 클라이언트의 시각이 잘못 된 경우나 악성 사용자의 조작 문제 |
| 처리 시각 | 사용자나 클라이언트의 조작이 불가 | 집계 결과의 정확도가 떨어진다 |
집계 윈도
- 윈도 타입: 데이터 스트림을 집계하는 방식에 따라 다양한 윈도 타입이 사용됩니다.
- Tumbling Window: 고정된 시간 간격으로 데이터 스트림을 분할합니다. 각 윈도는 겹치지 않습니다.
- Sliding Window: 새로운 이벤트가 발생할 때마다 윈도가 슬라이드 되어 최근 일정 시간 동안의 데이터를 포함합니다.
전달 보장
- 데이터 중복 제거: 클라이언트에서 의도적으로 혹은 서버 장애로 인해 중복된 이벤트가 발생할 수 있습니다. 중복 제거는 시스템의 데이터 정확성을 보장하는 중요한 요소입니다.
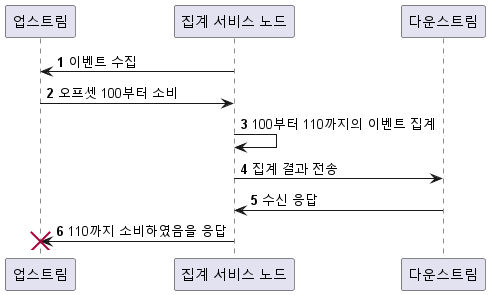
- 분산 트랜잭션 처리: 여러 컴포넌트 간의 데이터 일관성을 보장하기 위해 분산 트랜잭션을 처리하는 방법이 필요합니다. 이를 위해 2PC(2 Phase Commit), 3PC(3 Phase Commit), Sagas, 분산 로그 등의 기술을 활용할 수 있습니다.
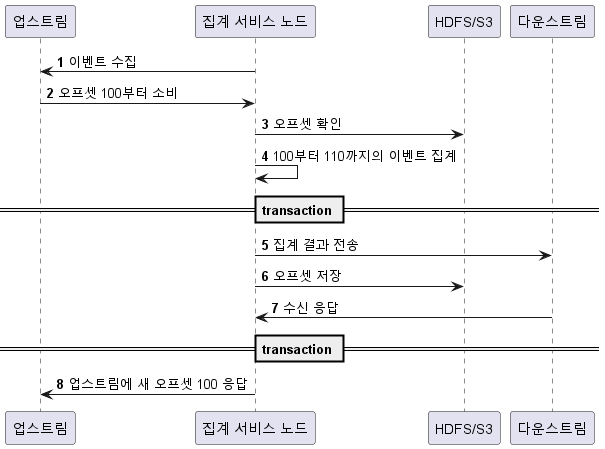 -분산 트랙잭션을 활용한 처리의 Sequence diagram 예시-
-분산 트랙잭션을 활용한 처리의 Sequence diagram 예시-
상세 설계 단계에서는 시스템의 정확성, 신뢰성 및 확장성을 보장하기 위한 다양한 기술적 전략을 고려해야 합니다. 각 컴포넌트의 역할과 상호 작용 방식을 명확히 정의하고, 데이터의 일관성과 정확성을 유지하는 메커니즘을 구축하는 것이 중요합니다.
시스템 규모 확장
집계 서비스의 규모 확장 사업이 성장함에 따라, 시스템은 늘어나는 트래픽을 효과적으로 처리할 수 있어야 합니다. 집계 서비스의 처리 대역폭을 높이기 위해 다음 방법을 고려할 수 있습니다:
- ad_id 샤딩: 각 ad_id에 대한 집계 작업을 분산시켜 처리할 수 있도록 ad_id를 기준으로 데이터를 샤딩하는 방법입니다.
- 자원 공급자 사용: YARN과 같은 자원 관리자를 사용하여 서비스를 분산시스템 환경에서 운영할 수 있습니다. 이를 통해 자동으로 자원을 할당받고, 확장 및 축소를 유연하게 관리할 수 있습니다.
데이터베이스의 규모 확장
- 카산드라: Cassandra는 자동으로 수평 확장이 가능한 데이터베이스로, 노드를 추가함으로써 쉽게 확장할 수 있습니다. 이는 높은 처리량과 대규모 데이터 세트를 관리하기에 적합합니다.
핫스팟 문제
특정 광고주나 광고 캠페인에 대한 클릭이 집중되어 핫스팟이 발생할 수 있습니다. 이를 해결하기 위해, 집계 노드에 더 많은 자원을 할당하여 처리 능력을 향상시키는 방법을 고려할 수 있습니다.
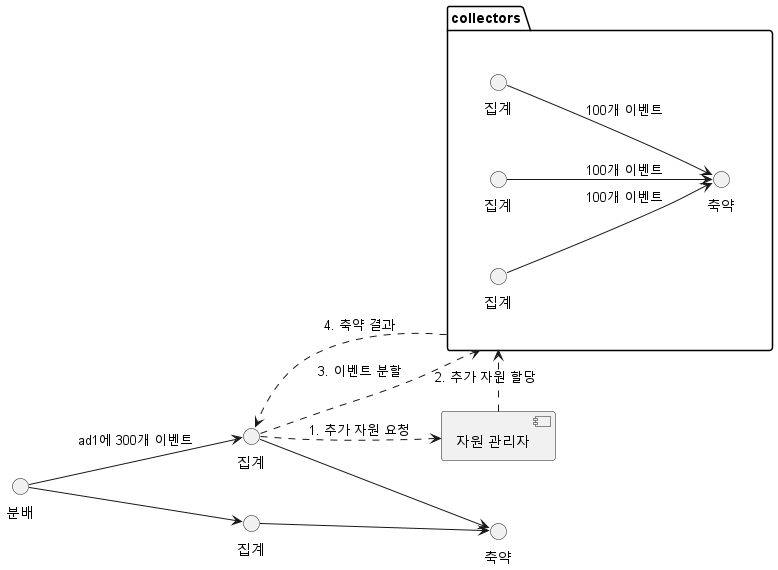
- 집계(limit 100) 서비스에 너무 많은 데이터(300)가 도착하여 자원 관리자에 추가 자원을 요청한다
- 자원 관리자는 추가 자원을 할당한다(2개)
- 이벤트를 세개 그룹으로 분리하여 처리한다
- reducer로 전달한다
결함 내성
집계 작업은 주로 메모리에서 이루어지기 때문에, 집계 노드에 문제가 발생하면 집계 결과가 손실될 위험이 있습니다. 이를 방지하기 위해, 정기적인 스냅샷을 통해 집계 상태를 저장하고, 필요시 이를 기반으로 시스템을 복구하는 방법을 고려할 수 있습니다.
데이터 모니터링 및 정확성
- 지속적 모니터링: 시스템의 각 단계에서 발생하는 지연 시간, 메시지 큐의 크기, 집계 노드의 시스템 자원 등을 지속적으로 모니터링하여, 시스템의 상태를 정확하게 파악하고 적절히 대응할 수 있어야 합니다.
- 데이터 무결성 보장: 데이터의 정확성은 매우 중요합니다. 따라서, 각 파티션에서 기록된 이벤트를 시간 순으로 정렬하여 실시간으로 처리된 결과와 비교하는 방법 등을 통해 데이터의 무결성을 지속적으로 검증할 필요가 있습니다.
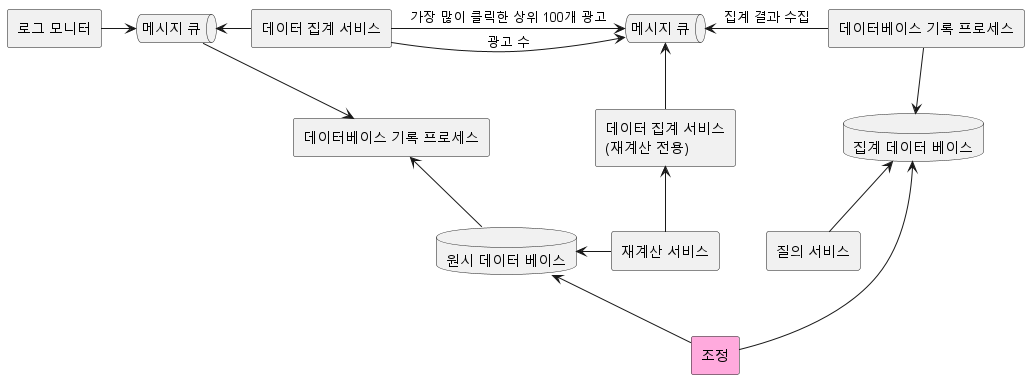
- 조정 서비스를 추가하여 두 데이터를 주기적으로 비교해 데이터의 무결성을 보장한다.
이와 같은 접근 방식을 통해, 시스템은 높은 처리량을 유지하면서도 안정성과 정확성을 보장할 수 있게 됩니다. 또한, 비즈니스의 성장과 함께 시스템이 유연하게 확장될 수 있는 기반을 마련할 수 있습니다.